This English edition walks through the same implementation ideas as the Korean post: parse the Gzip container, read the DEFLATE bitstream, rebuild Huffman tables, replay LZ77 back-references, and verify the footer. The goal is not to compete with production libraries, but to understand the moving parts clearly enough to implement a working decompressor yourself.

What you will learn
- How the Gzip header and footer are laid out
- Why DEFLATE reads bits in little-endian bit order
- How canonical Huffman codes are rebuilt from code lengths
- How dynamic Huffman blocks describe their own trees
- How LZ77 length/distance pairs reconstruct previous bytes
Prerequisites
- Rust 1.60 or later
- Comfort reading binary formats
- Basic understanding of bitwise operations
Environment Setup #
Start with a plain Rust binary project and avoid external decompression crates. That keeps the implementation focused on the format itself.
|
|
Prepare a small .gz file for iteration. A short text payload is enough for early testing because it lets you inspect both literals and repeated sequences.
Step 1: Parse the Gzip Container #
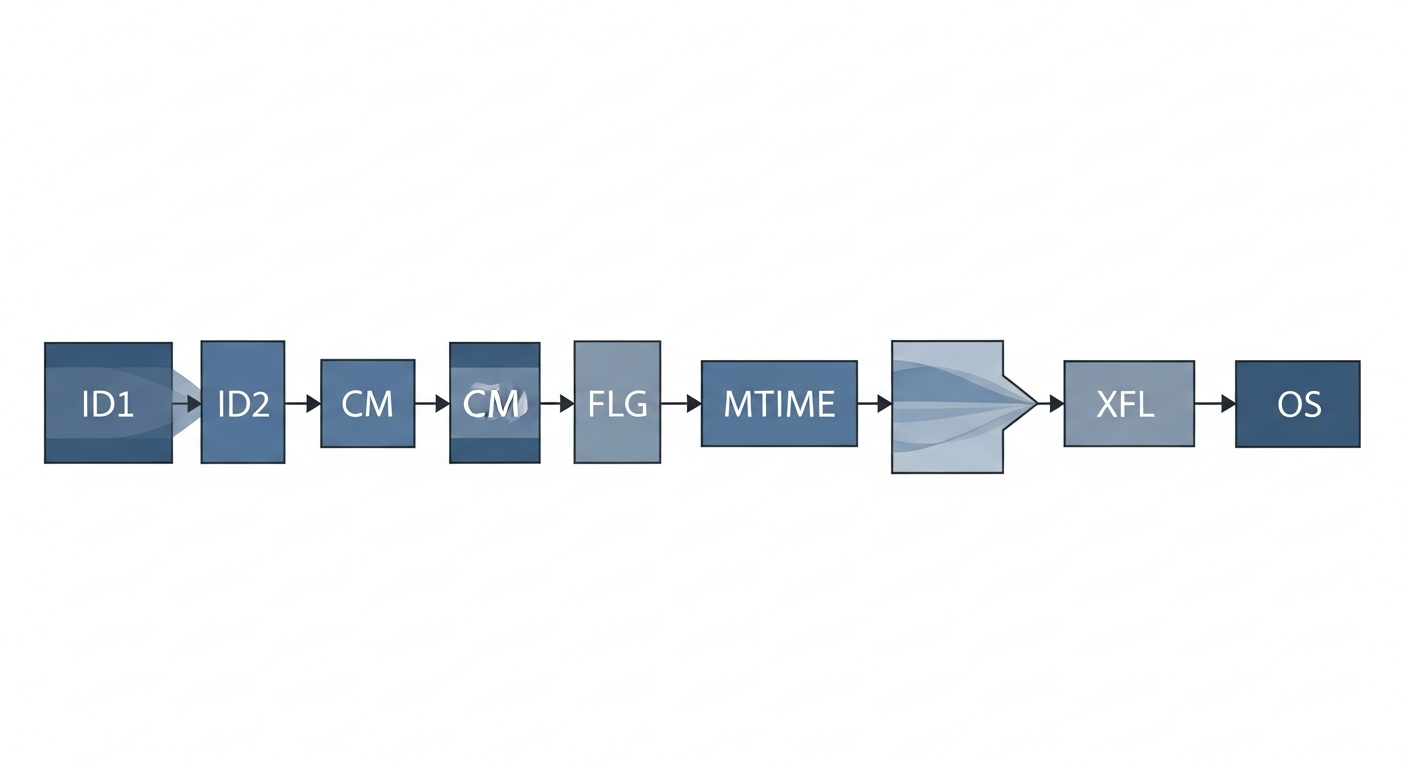
A Gzip file wraps raw DEFLATE data with a small header and an 8-byte footer. At minimum, you need to validate:
ID1 = 0x1fID2 = 0x8bCM = 8for DEFLATE- Optional header fields based on
FLG
After the compressed stream ends, the footer stores:
CRC32of the original dataISIZE, the uncompressed size modulo2^32
The practical lesson here is that your decompressor needs two layers of logic: the outer Gzip container parser and the inner DEFLATE decoder.
Step 2: Build a Bit Reader #
DEFLATE is bit-oriented, not byte-oriented. You cannot decode blocks correctly unless you have a helper that can pull arbitrary bit widths from the stream while keeping track of the current bit position.

Two details matter:
- DEFLATE consumes bits least-significant-bit first.
- Uncompressed blocks realign to the next byte boundary.
Once you have a reliable bit reader, the rest of the format becomes much easier to reason about.
Step 3: Rebuild Canonical Huffman Codes #
DEFLATE does not transmit a full pointer-based Huffman tree. Instead, it transmits code lengths and expects the decoder to rebuild the canonical code assignment.

The process is:
- Count how many codes exist for each bit length.
- Compute the first code for each length.
- Assign codes to symbols in order.
- Decode the input stream by walking bits until a valid symbol appears.
This compact representation is one of the reasons DEFLATE stays efficient.
Step 4: Decode DEFLATE Block Types #
Each DEFLATE block begins with BFINAL and BTYPE. From there, the decoder branches into one of three paths:
- Uncompressed block
- Fixed Huffman block
- Dynamic Huffman block

Dynamic Huffman blocks are the most interesting because they describe literal/length and distance trees inside the stream itself. That means your decoder must first decode the code-length alphabet, then use it to rebuild the actual trees used for the payload.
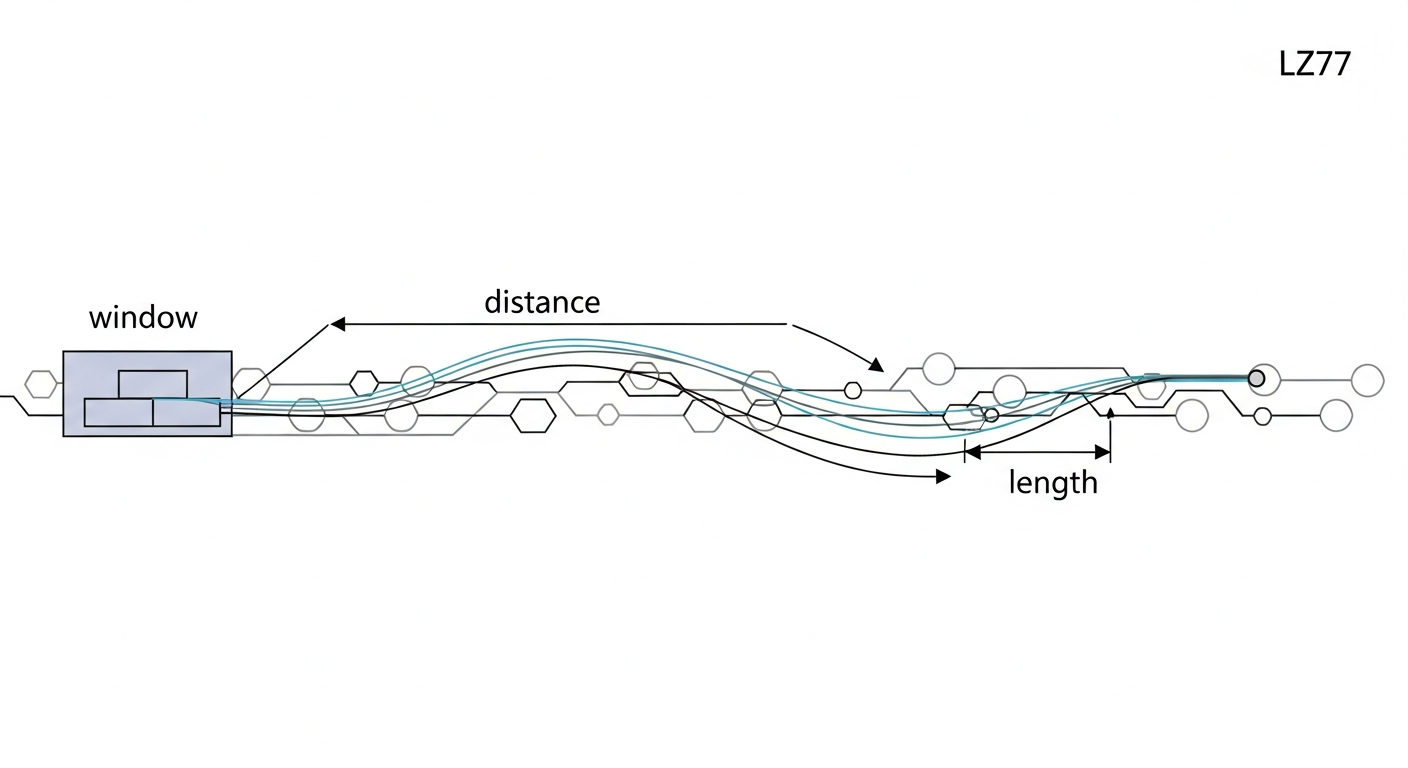
Step 5: Implement LZ77 Back-References #
Literal symbols write bytes directly to the output. Length/distance symbols mean “copy bytes that already exist in the sliding window.”

This is where the decompressor stops being a pure parser and starts reconstructing data. The output buffer itself becomes the dictionary. When a match is decoded, copy length bytes from distance bytes behind the current output position.
The implementation is small, but the indexing must be exact. Off-by-one mistakes here will corrupt the entire stream.
Step 6: Run the Block Loop and Verify the Footer #
The full decompression loop is straightforward once the pieces are in place:
- Read the next block header
- Decode the block according to its type
- Append reconstructed bytes to the output buffer
- Stop when
BFINAL = 1 - Read and verify
CRC32andISIZE

At that point you have a complete educational decompressor: small enough to understand in one sitting, but rich enough to cover the core mechanics used by real-world Gzip files.
Closing Notes #
If you want production-grade compatibility, you will still need more exhaustive error handling, broader test coverage, and support for edge cases across many archives. But as a learning project, a compact Rust implementation is enough to make the DEFLATE design feel concrete rather than mysterious.
The important result is not just that the code works. It is that you can now explain why it works: how the container is framed, how bits are consumed, how Huffman tables are reconstructed, and how repeated substrings are recovered through LZ77.