이 튜토리얼에서는 압축 알고리즘의 표준이라 할 수 있는 Gzip(GNU zip)의 압축 해제기를 Rust 언어를 사용하여 밑바닥부터 직접 구현해 봅니다. Gzip의 핵심인 DEFLATE 알고리즘(LZ77 + 허프만 코딩)의 동작 원리를 깊이 있게 이해하고, 외부 라이브러리 없이 순수 Rust 코드 250줄 내외로 동작하는 압축 해제기를 완성하는 것이 목표입니다.

배울 내용
- Gzip 파일 포맷의 헤더 및 푸터 구조 분석
- 비트 단위 데이터를 읽기 위한 Bit Reader 구현 기법
- 정규 허프만 트리(Canonical Huffman Tree)의 생성 및 디코딩 원리
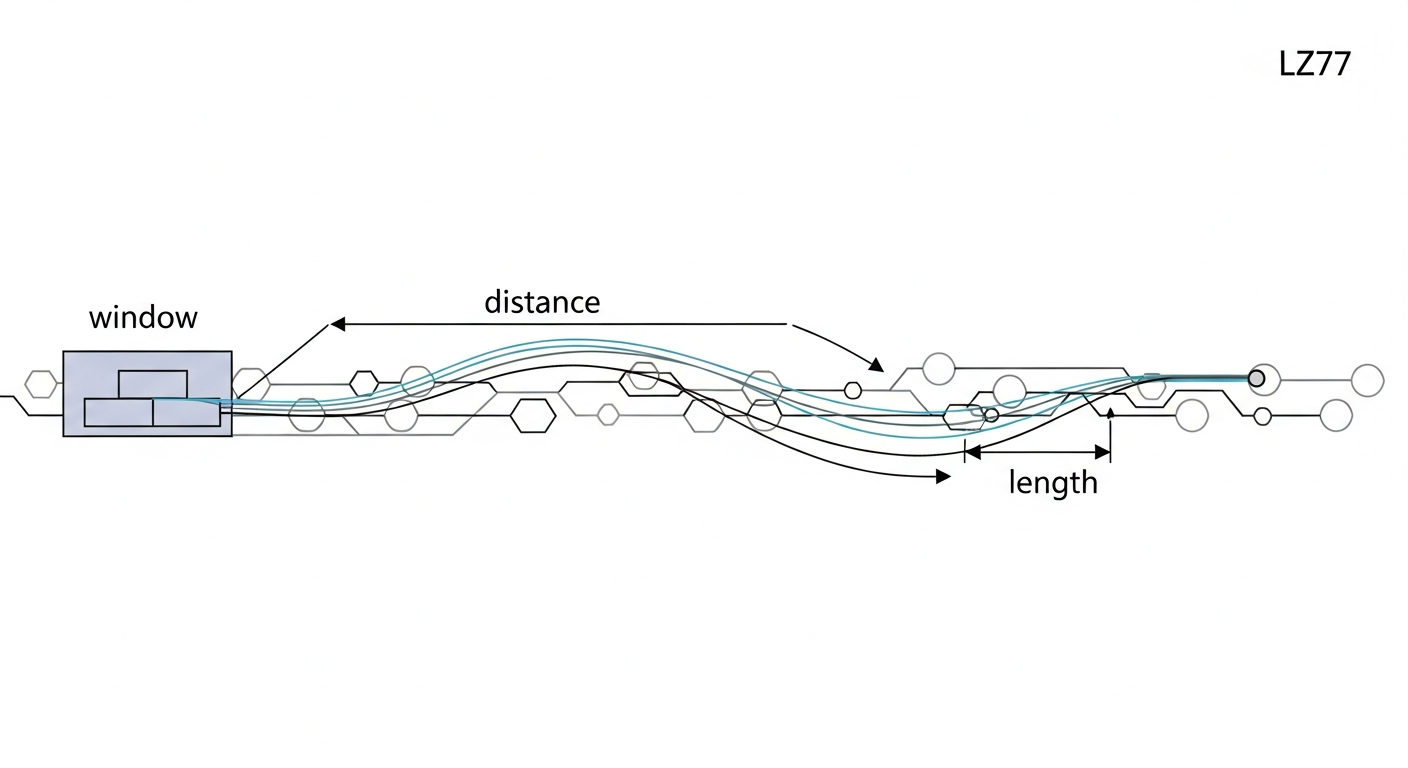
- LZ77 알고리즘의 슬라이딩 윈도우(Sliding Window)를 이용한 데이터 복원
- DEFLATE 알고리즘의 동적 허프만(Dynamic Huffman) 블록 파싱
사전 요구사항
- OS: Windows, macOS, Linux 등 Rust 지원 운영체제
- 언어: Rust (Edition 2021, 버전 1.60 이상 권장)
- 기타: 기본적인 비트 연산(Bitwise operation)에 대한 이해
환경 설정 #
먼저 새로운 Rust 프로젝트를 생성합니다. 외부 압축 해제 크레이트(crate)는 사용하지 않으며, 오직 Rust의 표준 라이브러리만을 사용하여 알고리즘의 본질에 집중합니다.
|
|
프로젝트가 생성되면 src/main.rs 파일을 열어 코드를 작성할 준비를 합니다. 테스트를 위해 간단한 텍스트 파일을 Gzip으로 압축하여 프로젝트 루트에 준비해 두는 것이 좋습니다.
|
|
단계 1: Gzip 파일 구조 이해 및 헤더 파싱 #
Gzip 파일은 단순히 압축된 데이터만 있는 것이 아니라, 파일의 메타데이터를 담고 있는 헤더(Header)와 무결성 검증을 위한 푸터(Footer)로 감싸져 있습니다.
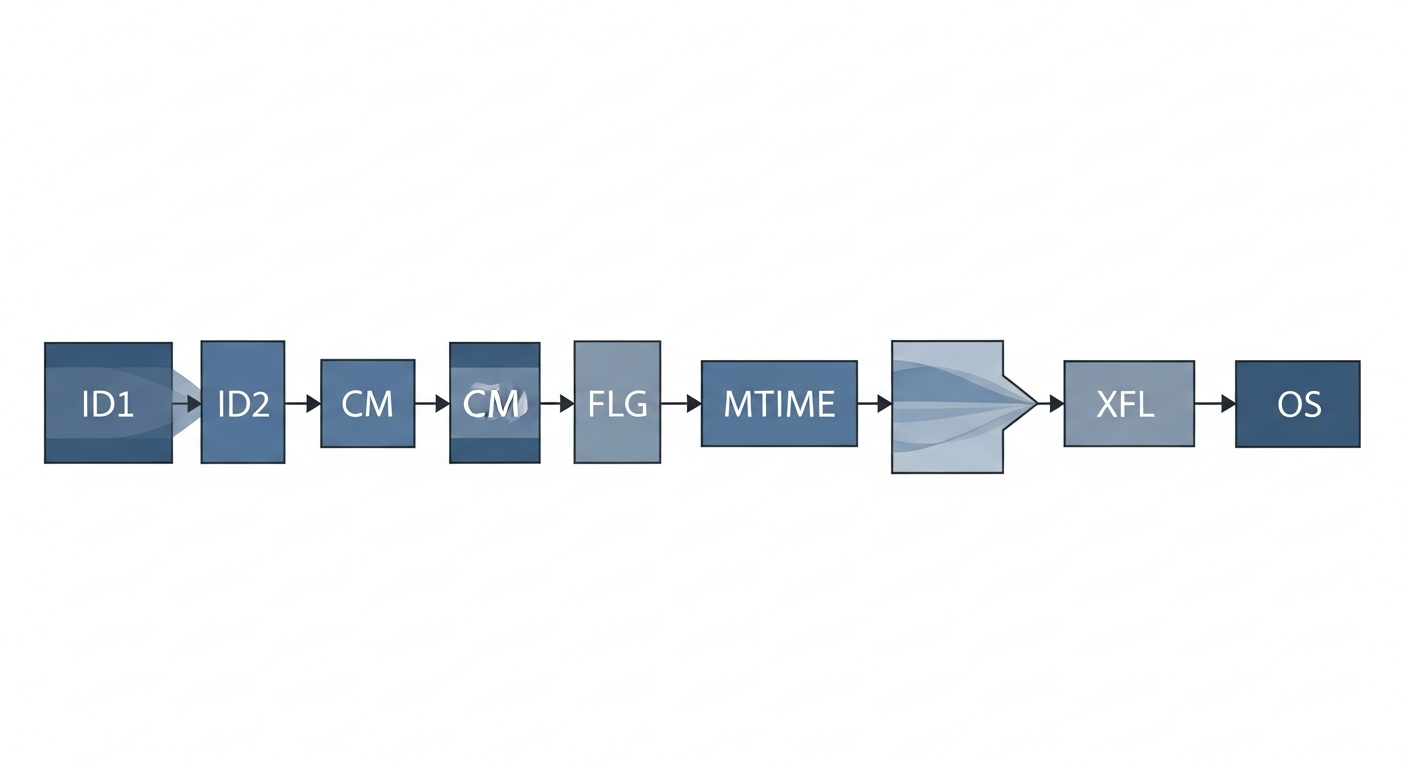
Gzip 헤더는 최소 10바이트로 구성되며 다음과 같은 구조를 가집니다:
- ID1 (1 byte): 매직 넘버
0x1F - ID2 (1 byte): 매직 넘버
0x8B - CM (1 byte): 압축 방식 (8 = DEFLATE)
- FLG (1 byte): 플래그 (파일 이름, 코멘트 등의 존재 여부)
- MTIME (4 bytes): 수정 시간
- XFL (1 byte): 추가 플래그
- OS (1 byte): 운영체제 정보
우선 파일을 읽고 이 10바이트 헤더를 검증하는 코드를 작성해 봅니다. 플래그에 따라 가변적인 추가 데이터(예: 원본 파일명)가 존재할 수 있으므로 이를 건너뛰는 로직도 필요합니다.
|
|
실행 결과 예시:
이 코드는 헤더를 성공적으로 파싱하면 GzipDecoder 인스턴스를 반환하고, 파일 형식이 맞지 않으면 에러를 발생시킵니다.
단계 2: 비트 스트림 리더(Bit Reader) 구현 #
DEFLATE 알고리즘은 바이트 단위가 아니라 비트(Bit) 단위로 데이터를 압축합니다. 따라서 바이트 스트림을 받아 원하는 개수만큼의 비트를 읽어내는 비트 리더(Bit Reader)가 필수적입니다.
주의할 점은 DEFLATE가 데이터를 읽을 때 LSB(Least Significant Bit, 최하위 비트) 부터 읽는다는 사실입니다. 예를 들어 바이트 11010010에서 3비트를 읽는다면 오른쪽 끝의 010을 먼저 읽게 됩니다.

효율적인 비트 처리를 위해 버퍼 역할을 할 bit_buffer와 현재 버퍼에 남은 비트 수를 나타내는 bit_count를 관리하는 구조체를 만듭니다.
|
|
이 BitReader는 앞으로 허프만 코드나 LZ77 길이/거리 코드를 읽을 때 핵심 엔진으로 작동합니다.
단계 3: 정규 허프만 트리(Canonical Huffman Tree) 구현 #
DEFLATE는 데이터의 출현 빈도에 따라 짧은 비트를 할당하는 허프만 코딩을 사용합니다. 일반적인 허프만 트리와 달리, DEFLATE는 트리의 형태를 전송하지 않고 각 심볼의 코드 길이(Code Length) 만 전송합니다. 이 길이 정보만으로 송수신자가 동일한 형태의 ‘정규 허프만 트리(Canonical Huffman Tree)‘를 재구성할 수 있습니다.
코드 길이 배열을 받아 실제 비트 코드를 할당하고, 비트 스트림으로부터 심볼을 디코딩하는 구조체를 작성합니다.

|
|
이 구현은 트리를 명시적인 노드 포인터 구조로 만들지 않고, 배열의 인덱스 계산만으로 디코딩을 수행하므로 메모리 사용량이 적고 속도가 매우 빠릅니다.
단계 4: DEFLATE 블록 파싱 - 동적 허프만 트리 #
DEFLATE 데이터는 여러 개의 블록(Block)으로 나뉩니다. 각 블록은 3비트의 헤더를 가지며, 1비트는 마지막 블록 여부(BFINAL), 2비트는 압축 유형(BTYPE)을 나타냅니다. 가장 복잡하고 자주 쓰이는 유형은 BTYPE = 10인 동적 허프만 압축(Dynamic Huffman Compression) 입니다.
동적 블록은 다음 순서로 데이터를 읽어야 합니다.
HLIT(5 bits),HDIST(5 bits),HCLEN(4 bits) 읽기- 코드 길이 알파벳(Code Length Alphabet)의 허프만 트리 구축
- 2번의 트리를 이용해 리터럴/길이(Literal/Length) 트리와 거리(Distance) 트리의 코드 길이 배열 디코딩
- 최종 리터럴 트리와 거리 트리 구축

|
|
단계 5: LZ77 압축 해제 로직 #
트리가 모두 구축되었다면 이제 실제 압축된 데이터를 풀 차례입니다. DEFLATE는 LZ77 알고리즘을 사용하여 반복되는 문자열을 “이전 데이터에서 N바이트 뒤로 가서 L바이트만큼 복사해라"라는 길이(Length) 와 거리(Distance) 정보로 대체합니다.
심볼 0~255는 리터럴 바이트 그대로 출력하고, 256은 블록의 끝(End of Block)을 의미합니다. 257~285는 복사할 길이(Length)를 나타냅니다.

|
|
out 벡터가 전체 출력 버퍼이자 LZ77의 슬라이딩 윈도우 역할을 동시에 수행합니다. 최근 압축 해제된 데이터가 벡터의 끝에 추가되므로, out.len() - distance 인덱스를 참조하여 과거 데이터를 쉽게 복사할 수 있습니다.
단계 6: 블록 루프 및 푸터 처리 #
마지막으로, 압축된 블록들을 순회하며 해제하고, Gzip 파일의 맨 끝에 위치한 8바이트 푸터(CRC32 및 원본 파일 크기)를 확인하는 메인 함수를 작성합니다. 분량 상 CRC32 검증 알고리즘 자체 구현은 생략하고 원본 크기 일치 여부만 확인합니다.
|
|

전체 코드 #
위에서 설명한 모든 요소를 결합한 전체 코드입니다. main.rs에 붙여넣고 실행해 볼 수 있습니다. (설명을 위해 BTYPE 0, 1 등 일부 엣지 케이스는 생략하고 가장 핵심인 동적 허프만 블록 위주로 구성했습니다.)
|
|
마치며 #
이 튜토리얼을 통해 복잡해 보이는 Gzip과 DEFLATE 알고리즘을 250줄 남짓한 Rust 코드로 분해하여 직접 구현해 보았습니다. 비트 스트림 처리, 정규 허프만 트리의 배열 기반 구축 방법, 그리고 LZ77의 슬라이딩 윈도우 기법 등은 압축 알고리즘뿐만 아니라 시스템 프로그래밍 전반에 걸쳐 매우 유용한 개념입니다.
- Rust의 소유권과 안전성을 바탕으로 메모리 오류 없이 바이너리 데이터를 파싱할 수 있었습니다.
- 배열 인덱스 계산을 통한 허프만 트리 최적화 기법을 배웠습니다.
- 데이터 압축 알고리즘의 표준인 DEFLATE의 내부 구조를 이해했습니다.
다음 단계 제안:
이번에 생략된 ‘고정 허프만 블록(Fixed Huffman Block)’ 처리 로직과 푸터의 ‘CRC32 무결성 검증’ 로직을 직접 구현하여 추가해 보세요. 또한 std::io::Write 트레이트를 활용하여 메모리 버퍼가 아닌 파일 스트림으로 직접 압축을 해제하도록 최적화해 보는 것도 훌륭한 학습이 될 것입니다.