최근 인공지능 분야에서 SLM(Small Language Model) AI 모델이 주목받고 있습니다. 거대 언어 모델(LLM)의 등장과 함께 AI 모델의 경량화 필요성이 대두되면서, SLM은 제한된 자원에서도 효율적인 성능을 발휘하는 핵심 기술로 자리매김하고 있습니다. 이 글에서는 SLM AI 모델이 무엇인지, 왜 중요한지, 그리고 실제 산업에서 어떻게 활용될 수 있는지 상세히 다루어 독자 여러분이 SLM의 잠재력을 이해하고 실제 프로젝트에 적용할 수 있도록 돕겠습니다.
SLM은 LLM에 비해 적은 매개변수를 가지지만, 특정 도메인이나 작업에 최적화되어 높은 효율성과 빠른 응답 속도를 제공합니다. 이는 온디바이스 AI, 엣지 컴퓨팅, 비용 효율적인 AI 서비스 구현 등 다양한 분야에서 혁신적인 가능성을 열어주고 있습니다.
SLM AI 모델이란 무엇인가요? #
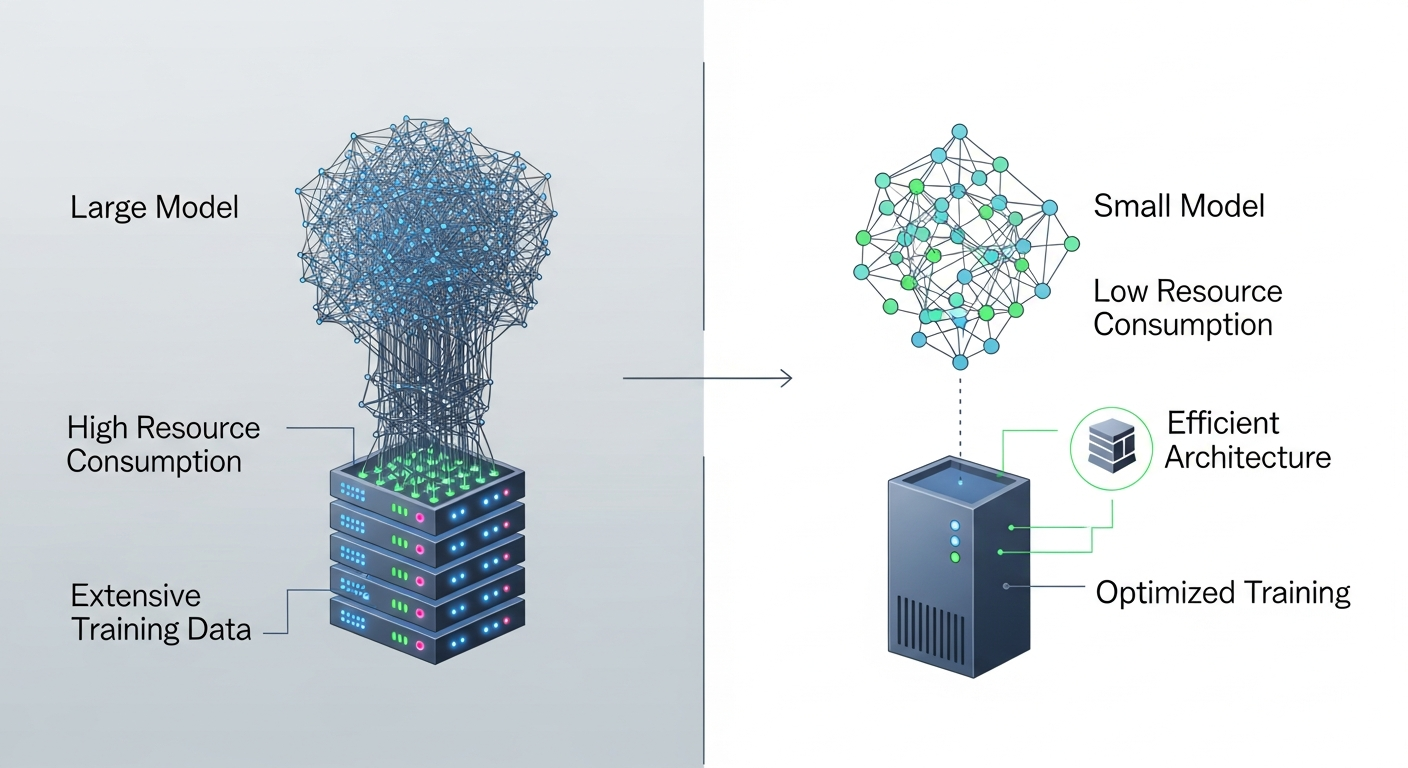
SLM(Small Language Model) AI 모델은 일반적으로 수십억 개 이상의 매개변수를 가진 LLM(Large Language Model)과 달리, 수백만에서 수억 개 수준의 매개변수를 가지는 경량화된 언어 모델을 의미합니다. 이러한 규모의 차이는 모델의 학습, 배포 및 운영 방식에 큰 영향을 미칩니다.
SLM의 주요 특징:
- 적은 매개변수: 모델의 크기가 작아 메모리 사용량과 연산량이 적습니다.
- 빠른 추론 속도: 모델이 작아 동일한 하드웨어에서 더 빠르게 결과를 도출할 수 있습니다.
- 낮은 운영 비용: 적은 컴퓨팅 자원으로도 운영이 가능하여 비용 효율적입니다.
- 특정 도메인 최적화: 범용적인 지식보다는 특정 작업이나 도메인에 특화된 학습을 통해 높은 정확도를 달성합니다.
- 온디바이스 배포 용이성: 스마트폰, IoT 기기 등 제한된 자원의 엣지 디바이스에 직접 배포하기에 적합합니다.
LLM과의 비교:
| 특징 | LLM (Large Language Model) | SLM (Small Language Model) |
|---|---|---|
| 매개변수 규모 | 수십억 ~ 수천억 개 | 수백만 ~ 수억 개 |
| 학습 데이터 | 방대한 웹 데이터, 다양한 도메인 | 특정 도메인, 목적에 맞는 정제된 데이터 |
| 추론 속도 | 느림 (고성능 GPU 필수) | 빠름 (CPU, 엣지 디바이스 가능) |
| 자원 요구량 | 높음 (고성능 서버, GPU) | 낮음 (일반 서버, 온디바이스) |
| 주요 활용 분야 | 범용 대화, 창작, 복잡한 문제 해결 | 특정 태스크 자동화, 온디바이스 AI, 비용 효율적 서비스 |
| 비용 | 높음 (학습, 추론, 운영) | 낮음 (학습, 추론, 운영) |

SLM의 주요 장점과 활용 분야 #
SLM은 그 경량성 덕분에 LLM이 해결하기 어려웠던 다양한 문제들을 해결하고 새로운 기회를 창출합니다.
1. 온디바이스 AI 및 엣지 컴퓨팅:
- 장점: 인터넷 연결 없이 기기 자체에서 AI 추론이 가능하여 지연 시간을 줄이고 개인 정보 보호를 강화합니다. 클라우드 의존도를 낮춰 비용을 절감합니다.
- 활용 예시:
- 스마트폰: 오프라인 음성 인식, 실시간 번역, 이미지 처리 (예: 사진 필터, 객체 인식)
- IoT 기기: 스마트 홈 기기(음성 비서), 웨어러블 기기(활동 모니터링), 산업용 센서 데이터 분석
- 자율주행차: 실시간 도로 상황 인식, 운전자 보조 시스템
2. 비용 효율적인 AI 서비스:
- 장점: LLM 학습 및 추론에 필요한 막대한 컴퓨팅 자원과 비용을 크게 절감할 수 있습니다.
- 활용 예시:
- 기업 내부 챗봇: 특정 업무(HR, IT 지원)에 특화된 챗봇을 저렴한 비용으로 구축 및 운영
- 콘텐츠 요약/분류: 뉴스 기사 요약, 고객 문의 분류 등 반복적인 텍스트 처리 작업 자동화
- 개인화 추천 시스템: 사용자 행동 패턴 분석을 통한 맞춤형 상품/콘텐츠 추천
3. 데이터 프라이버시 및 보안 강화:
- 장점: 민감한 데이터가 클라우드로 전송되지 않고 로컬 기기 내에서 처리되므로 데이터 유출 위험을 줄입니다.
- 활용 예시:
- 의료 분야: 환자 기록 분석, 진단 보조 (개인 건강 정보 유출 방지)
- 금융 분야: 사기 탐지, 이상 거래 감지 (금융 정보 보안 강화)
- 기업 내부 문서 검색: 민감한 기업 정보가 외부 서버로 전송되지 않도록 로컬에서 처리
4. 빠른 개발 및 배포 주기:
- 장점: 모델 크기가 작아 학습 시간이 짧고, 배포 및 업데이트가 용이하여 시장 변화에 빠르게 대응할 수 있습니다.
- 활용 예시:
- A/B 테스트: 다양한 SLM 모델을 빠르게 테스트하고 최적의 모델을 적용
- 수직 산업별 특화 AI: 특정 산업(법률, 제약 등)의 요구사항에 맞춰 신속하게 맞춤형 AI 모델 개발
SLM 모델 구축 및 최적화 전략 #
효율적인 SLM 모델을 구축하고 활용하기 위해서는 몇 가지 핵심 전략이 필요합니다.
1. 도메인 특화 데이터셋 구축:
- SLM은 범용적인 지식보다는 특정 도메인에 대한 깊이 있는 이해를 필요로 합니다.
- 전략:
- 타겟 애플리케이션에 맞는 고품질의 정제된 데이터를 수집합니다.
- 도메인 전문가와 협력하여 데이터 어노테이션(Annotation)을 수행합니다.
- 데이터 증강(Data Augmentation) 기법을 활용하여 데이터 부족 문제를 해결합니다.
2. 모델 경량화 기법 적용:
모델의 크기를 줄이고 추론 속도를 높이기 위한 다양한 기법이 있습니다.
- 지식 증류(Knowledge Distillation): 대규모 선생(Teacher) 모델의 지식을 작은 학생(Student) 모델로 전이시키는 기법입니다.
- 선생 모델이 예측한 소프트 레이블(Soft Label)을 학생 모델 학습에 활용합니다.
Teacher Model (Large)→Student Model (Small)
- 가지치기(Pruning): 모델의 가중치 중 중요도가 낮은 부분을 제거하여 모델을 희소하게 만드는 기법입니다.
Weight Matrix→Sparse Weight Matrix
- 양자화(Quantization): 모델의 가중치를 부동소수점에서 더 낮은 비트의 정수형으로 변환하여 모델 크기와 연산량을 줄입니다.
Float32 Weights→Int8 Weights
- 저랭크 근사(Low-Rank Approximation): 모델의 가중치 행렬을 낮은 랭크의 두 행렬의 곱으로 근사하여 매개변수 수를 줄입니다.
W (m x n)→U (m x k) * V (k x n)(k « min(m, n))
3. 효율적인 학습 및 파인튜닝:
- 전이 학습(Transfer Learning): 대규모 데이터로 사전 학습된 모델을 가져와 특정 작업에 맞게 파인튜닝합니다.
- PEFT (Parameter-Efficient Fine-Tuning): 전체 모델의 매개변수를 업데이트하는 대신, 소수의 추가 매개변수만 학습하여 효율성을 높입니다. (예: LoRA)
Pre-trained Model + Small Adaptor Module (Train only Adaptor)
- 분산 학습(Distributed Training): 여러 GPU나 서버를 활용하여 학습 시간을 단축합니다.
4. 런타임 최적화:
- ONNX Runtime, OpenVINO, TensorRT 등 추론 엔진 활용: 특정 하드웨어에 최적화된 추론 환경을 구축하여 속도를 극대화합니다.
- 하드웨어 가속기 활용: NPU(Neural Processing Unit) 등 AI 연산에 특화된 하드웨어를 활용합니다.
SLM 활용 예시: 고객 서비스 챗봇 #
다음은 SLM을 활용하여 특정 제품에 대한 고객 문의를 처리하는 챗봇을 구축하는 시나리오입니다.
시나리오: “스마트워치 A1000"에 대한 고객 문의를 응대하는 챗봇 목표: 고객 문의에 신속하고 정확하게 답변하며, 복잡한 문의는 상담원에게 연결
1. 데이터셋 구축:
- 스마트워치 A1000 관련 FAQ, 제품 설명서, 기존 고객 문의 로그 등을 수집하고 정제합니다.
- 질문-답변 쌍 형태로 데이터를 구성합니다. (예: “A1000 배터리 수명은?”, “A1000 방수 기능은?”)
2. SLM 모델 선택 및 파인튜닝:
- 작은 규모의 사전 학습된 언어 모델(예: BERT-tiny, DistilBERT)을 선택합니다.
- 구축된 스마트워치 A1000 데이터셋으로 SLM을 파인튜닝합니다.
- 입력: 고객 문의 문장 (예: “워치 배터리가 빨리 닳아요.”)
- 출력: 관련 FAQ 답변 또는 상담원 연결 분류 (예: “배터리 문제 해결 가이드”, “상담원 연결 필요”)
3. 모델 배포 및 연동:
- 파인튜닝된 SLM 모델을 웹 서버 또는 엣지 디바이스(앱 내장)에 배포합니다.
- 챗봇 인터페이스와 연동하여 고객 문의를 SLM으로 전달하고, SLM의 답변을 고객에게 보여줍니다.
4. 폴백(Fallback) 전략:
- SLM이 답변하기 어려운 복잡한 문의나 모델의 신뢰도가 낮은 답변의 경우, 자동으로 상담원에게 연결하는 로직을 구현합니다.
고객 문의→SLM→(답변 가능)→답변 제공고객 문의→SLM→(답변 불가능/신뢰도 낮음)→상담원 연결
이러한 방식으로 SLM은 특정 제품/서비스에 특화된 고품질의 고객 응대 서비스를 저비용으로 제공할 수 있습니다.

마치며 #
SLM AI 모델은 LLM의 한계를 보완하고, AI 기술의 보편화와 실용화를 앞당기는 중요한 축입니다. 경량화된 모델은 온디바이스 AI, 비용 효율적인 서비스, 그리고 강화된 데이터 프라이버시 등 다양한 이점을 제공하며, 앞으로 더욱 많은 산업 분야에서 혁신을 이끌 것입니다.
SLM의 잠재력을 최대한 활용하기 위해서는 도메인 특화 데이터셋 구축, 모델 경량화 기법 적용, 그리고 효율적인 학습 및 배포 전략 수립이 필수적입니다. 지금 바로 여러분의 비즈니스에 SLM을 적용하여 새로운 가치를 창출해 보시길 바랍니다!
